最近,AI大神、OpenAI 创始成员和Tesla 前 AI 总监 Andrej Karpathy 的一条 LLM Knowledge Bases 的X帖子 刷爆了 AI 圈。Karpathy 分享了自己如何用 LLM构建个人知识库的实践:Token 消耗不再主要用来“写代码”,而是用来“操作知识”。
Karpathy 把这套系统叫 LLM Knowledge Base(或 LLM Wiki),核心思路极其简单但有效:把原始资料扔进一个文件夹,让 AI 自动“编译”成一套互相链接的 Markdown Wiki。不用手动编辑,AI 负责整理、维护、更新、回答问题、并定期“健康检查”。
Karpathy 第二天又发了一条 follow-up 的 帖子:把整个想法浓缩成一个 GitHub Gist,强调在 LLM Agent 时代,分享“具体代码”已经过时;分享想法就够了,Agent 会根据你的需求自动定制实现。
Karpathy 的LLM Wiki 本质是一个由 LLM 自动生成、维护、交叉链接的 Markdown 知识系统。与传统知识管理“问问题再检索”不同,LLM Wiki 是“提前编译知识” ,AI 提前把知识结构化、持久化,让每次提问都站在“已编译”的基础上。
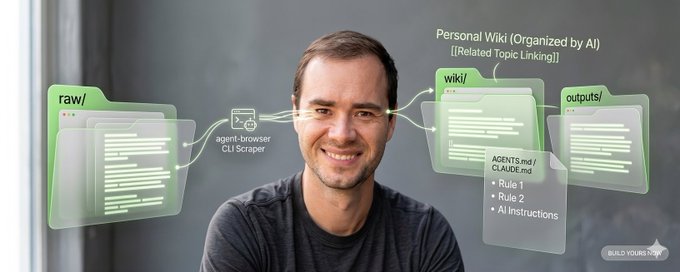
LLM Wiki 的核心思路:三层结构 + AI 做“程序员”
Karpathy 的LLM Wiki 系统极其“极简主义”:
1、raw/ 文件夹(原始资料库)
把所有研究素材——论文、文章、GitHub 仓库、数据集、图片等——扔进一个 raw/ 目录。Karpathy 用 Obsidian Web Clipper 浏览器扩展把网页文章转成 Markdown 文件,同时把相关图片下载到本地,方便 LLM 通过视觉能力引用。
2、wiki/ 文件夹(AI 编译的知识库)
这是LLM Wiki的核心创新。不是简单地索引文件,而是让 LLM 去”编译”它们。它读取 raw/ 中的数据,然后写出一个结构化的 Wiki:生成摘要、识别核心概念、撰写百科式文章,并且在相关概念之间创建反向链接。LLM 不只是检索者,它是知识库的主要作者和编辑。
3、Schema / AGENTS.md(规则说明文件)
一份纯文本配置文件,告诉 LLM 如何操作 。这个文件定义了摄入规则、问答行为、一致性检查标准等等。人和 LLM 会随着时间推移共同迭代优化这个 Schema。
IDE = Obsidian
Obsidian 只是“前端查看器”。AI 才是真正的“程序员”——它写 Wiki、维护 Wiki、更新 Wiki。你几乎不手动碰文件。
LLM Wiki 的核心工作流闭环
Karpathy 特别强调LLM Wiki不是“一次性导入”,而是持续复利增长( Compounding)。
支撑LLM Wiki持续复利增长的核心工作流:
- Ingest(入库):新增资料,AI 自动摘要、分类、链接到已有文章。
- Compile(编译):LLM 自动对知识进行总结、分类、建立链接、更新已有页面
- Query & Output(提问 + 输出):对 Wiki 提问题,AI 输出 Markdown、Marp 幻灯片、图表等,同时把输出结果存回 Wiki,让知识持续更新,实现复利增长
- Lint / Health Check(体检):定期让 AI 扫描整个 Wiki,找出矛盾、缺失、孤儿页面、潜在新文章建议,甚至用 Web search 补全信息。
- Extra Tools(扩展工具):搜索索引、CLI 工具、合成数据生成等,由 AI 调用或 Vibe Coding 出来,增强 Wiki能力。
通过 Ingest → Compile → Query/Output → Lint → Extra Tools 核心工作流实现了知识的闭环管理,每一次循环都让 Wiki 更聪明、更完整。
受Karpathy 思路的启发,有很多人打造自己的LLM Wiki,一些值得参考的玩法:
https://x.com/NickSpisak_/status/2040448463540830705
https://x.com/garrytan/status/2040797478434549792
https://x.com/alliekmiller/status/2040884878229565816
https://x.com/FarzaTV/status/2040563939797504467
Graphify
https://github.com/safishamsi/graphify
Karpathy LLM Wiki方法论的Skill