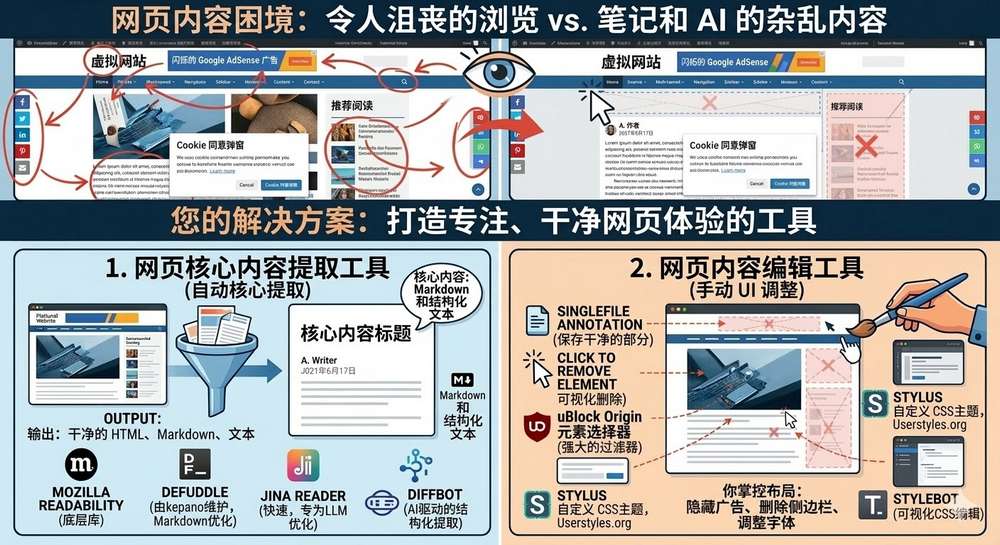
在浏览网页时,我们常常遇到这样的困扰:文章被 Google Adsense广告、侧边栏、推荐阅读、Cookie隐私弹出、浮动导航栏包围,阅读体验大打折扣。另一方面,当我们想将网页内容用于笔记、AI分析、存档时,需要干净的核心内容,而非一堆包含乱七八糟HTML元素的完整页面。
汇总一下能够帮助打造更专注、更干净的浏览与内容消费体验的工具,整体而言,有两类工具:
- 网页核心内容提取工具:自动识别并剥离无关元素,只保留标题、正文、作者、日期等主要内容(常输出干净Markdown或结构化文本)
- 网页内容编辑工具:允许用户手动或半自动修改页面UI,去除/隐藏/调整任意元素(类似“所见即改”)
网页核心内容提取工具
网页内容提取的核心目标是:从复杂 HTML 中提取“真正有价值的正文”,典型去除内容包括:
- 广告(Ads)
- 导航栏(Nav)
- 推荐内容(Recommendations)
- 评论区(Comments)
最终输出:
- 只包含核心内容的HTML
- Markdown
- 纯文本
此类工具的鼻祖是Mozilla Readability,但由于Mozilla Readability 更新维护较慢,如今已涌现更多现代替代品,尤其适合AI时代(LLM/RAG需要干净输入)。
Mozilla Readability:
https://github.com/mozilla/readability
Firefox 阅读模式(Reader View)的底层库
Defuddle:
https://github.com/kepano/defuddle
由Obsidian创始人kepano维护,是Readability的现代升级版。
Jina Reader
零配置、速度极快、专为LLM优化。免费额度充足,许多人拿它做日常“网页阅读器”。
Diffbot
收费(有免费额度)服务。基于机器学习 + 计算机视觉 的网页数据提取平台,提供 API 将网页转换为结构化数据。不仅支持提取网页核心内容,而且能理解整个网页的类型与结构
其他工具:
Trafilatura:https://github.com/adbar/trafilatura
Newspaper3k :https://github.com/codelucas/newspaper
网页内容编辑工具
SingleFile Annotation(标注并保存该页面) 或保存选中部分
https://www.getsinglefile.com/
Click to Remove Element
https://blade.sk/projects/ctre/
可视化移除指定的页面要素
uBlock Origin Element picker
https://github.com/gorhill/ublock/wiki/Element-picker
uBlock Origin 的元素移除器功能超级强大,可以永久删除页面元素或编写过滤规则移除指定页面元素
Stylus
https://github.com/openstyles/stylus
允许为特定的网站编写自定义的 CSS 样式表,userstyles.org 上有海量主题可使用
Stylebot
与Stylus功能类似,提供可视化编辑功能
有编程基础的,可以基于更强大的Tampermonkey自定义网页内容。