Markdown 格式由于AI友好,已成为AI时代的缺省文件格式,但在科研、工程、法律等领域,PDF 依然是信息传播的“终极格式”。
Google Translate、DeepL、沉浸式翻译、Trancy等翻译工具都支持PDF 翻译,但经常使用这些翻译工具翻译PDF格式的论文的人都会遇到一大堆问题,包括:
- 行内/行间数学公式:复制出来要么乱码要么残缺,翻译之后位置全错
- 双栏论文版式:复制顺序会跨栏,读起来跟乱码差不多
- 代码块和命令行参数:翻译模型会把 –port 8080 翻成 –端口 8080
- 扫描版 PDF / 图片型 PDF:根本没文字层,复制不出东西
- 复杂表格、目录、页眉页脚:经常会排版混乱
也正因为这些痛点,最近一段时间涌现出众多专门做”保留版面 PDF 翻译”的开源项目,包括:PDFMathTranslate、BabelDOC、PolyglotPDF 、pdf2zh-desktop 等。这些项目核心的技术实现方案都大致为:
版面识别 → 文字 + 坐标提取 → 翻译 → 按原坐标回填 → 重新渲染 PDF
听起来简单,做好却很难。版面识别要够准,公式不能被错切,回填的字号要会自适应,扫描型 PDF 还得先做 OCR,一大堆问题。
RetainPDF 是最近在GitHub上备受关注的PDF翻译类开源项目,项目的核心功能很明确:在保留版面、公式与结构的前提下进行 PDF 翻译。
RetainPDF:https://github.com/wxyhgk/retain-pdf
RetainPDF的最大卖点是全链路保留排版:
- 支持扫描型/图片型PDF:内置OCR识别,自动提取文本后再翻译,不会因为是扫描件就直接放弃。
- 复杂公式处理:精准识别并保留LaTeX行内公式,避免翻译后公式“崩坏”。
- 智能避免误翻:代码块、专有名词、表格结构可自定义规则保护。
- 排版重建:使用Typst等排版引擎重建文档,保持原始布局、图片位置、章节结构。
- 输出优化:翻译后PDF体积控制良好,支持压缩和字体自适应。
- 全栈设计:前后端分离,既能直接用桌面端,也支持Docker部署和API二次开发。
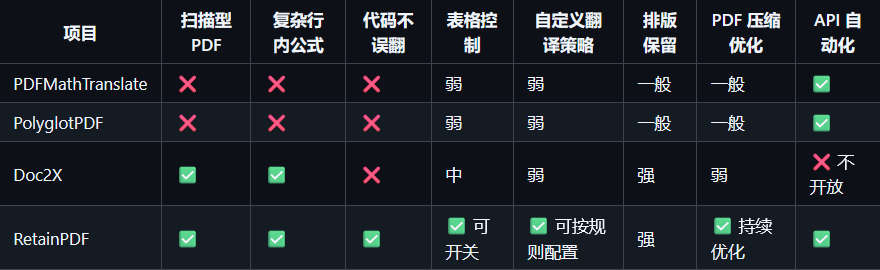
RetainPDF 与 PDFMathTranslate、PolyglotPDF、Doc2X 的功能对比:
RetainPDF 还提供多组效果对比图,包括SCI论文翻译后公式和参考文献完整保留;扫描版手册OCR后排版一致;图书类长文档章节结构丝滑。
安装使用上,RetainPDF 提供了三种方式,适合不同场景:
- PC客户端:支持Windows、macOS、Linux,下载安装即可使用
- Docker部署:适合团队/局域网使用
- 二次开发:提供完整API文档和模块化架构,适合有定制需求的开发者
使用流程超级简单:上传PDF → 自动OCR(扫描件)→ 智能翻译 → 排版重建 → 下载结果PDF。整个过程本地化程度高,隐私更有保障。
RetainPDF的出现,较好解决了”扫描PDF+复杂公式+完美排版“ 的需求痛点,值得需要经常翻译PDF的使用。
RetainPDF、PDFMathTranslate、BabelDOC、PolyglotPDF、Doc2X、pdf2zh-desktop 的核心功能对比:
